Learning objectives
By the end of this module you will be able to:
- Explore the association between two continuous variables using a scatter plot;
- Estimate and interpret correlation coefficients;
- Estimate and interpret parameters from a simple linear regression;
- Assess the assumptions of simple linear regression;
- Test a hypothesis using regression coefficients.
Optional readings
Kirkwood and Sterne (2001); Chapter 10. [UNSW Library Link]
Bland (2015); Chapter 11. [UNSW Library Link]
8.1 Introduction
In Module 5, we saw how to test whether the means from two groups are equal - in other words, whether a continuous variable is related to a categorical variable. Sometimes we are interested in how closely two continuous variables are related. For example, we may want to know how closely blood cholesterol levels are related to dietary fat intake in adult men. To measure the strength of association between two continuously distributed variables, a correlation coefficient is used.
We may also want to predict a value of a continuous measurement from another continuous measurement. For example, we may want to know predict values of lung capacity from height in a community of adults. A regression model allows us to use one measurement to predict another measurement.
Although both correlation coefficients and regression models can be used to describe the degree of association between two continuous variables, the two methods provide different information. It is important to note that both methods summarise the strength of an association between variables, and do not imply a causal relationship.
8.2 Notation
In this module, we will be focussing on the association between two variables, denoted \(x\) and \(y\).
There may be cases where it does not matter which variable is denoted \(x\) and which is denoted \(y\), however this is rare. We are usually interested in whether one variable is associated with another. If we believe that a change in \(x\) will lead to a change in \(y\), or that \(y\) is influenced by \(x\), we define \(y\) as the outcome variable and \(x\) as the explanatory variable.
8.3 Correlation
We use correlation to measure the strength of a linear relationship between two variables. Before calculating a correlation coefficient, a scatter plot should first be obtained to give an understanding of the nature of the relationship between the two variables.
Worked Example
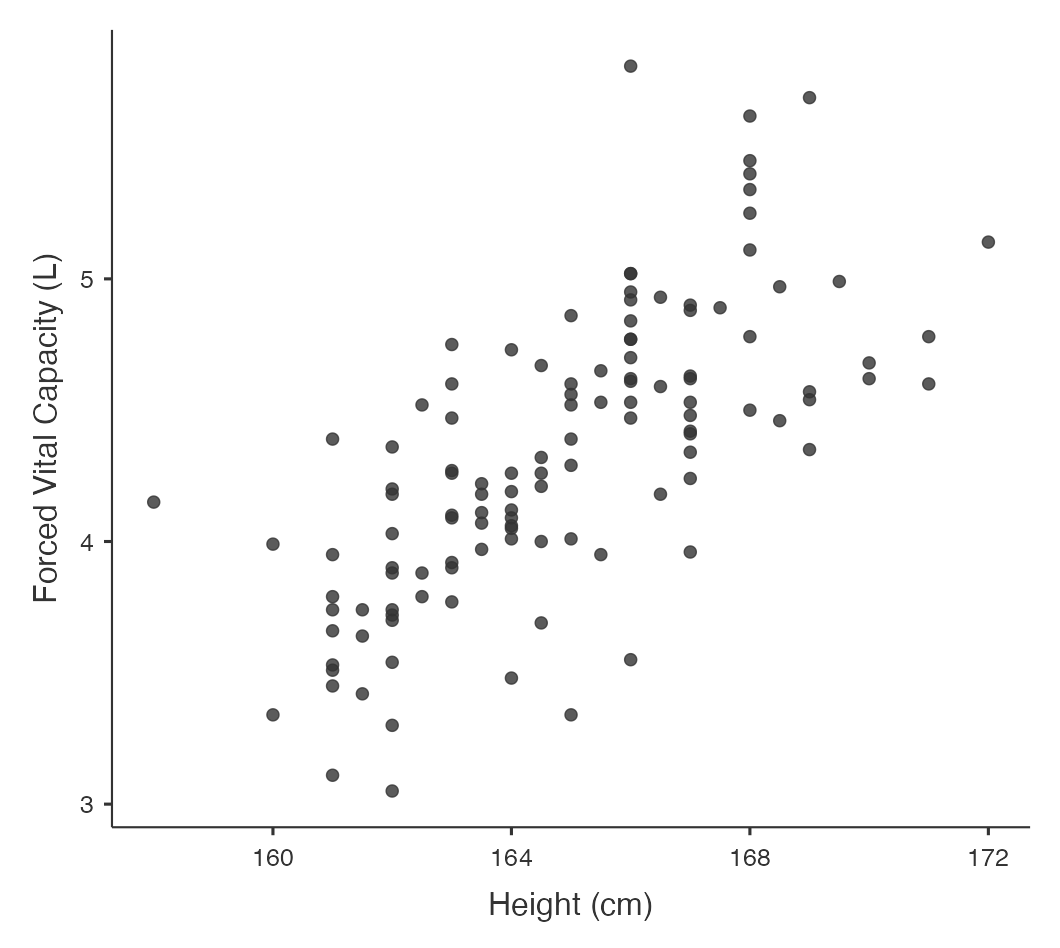
The file mod08_lung_function.csv has information about height and lung function collected from a random sample of 120 adults. Information was collected on height (cm) and lung function, which was measured as forced vital capacity (FVC), measured in litres. We can obtain a scatter-plot shown in Figure 8.1, where the outcome variable (\(y\)) is plotted on the vertical axis, and the explanatory variable (\(x\)) is plotted on the horizontal axis.
Figure 8.1 shows that as height increases, lung function also increases, which is as expected. One or two of the data points are separated from the rest of the data but are not so far away as to be considered outliers because they do not seem to stand out of other observations.
Correlation coefficients
A correlation coefficient (r) describes how closely the variables are related, that is the strength of linear association between two continuous variables. The range of the coefficient is from +1 to −1 where +1 is a perfect positive association, 0 is no association and −1 is a perfect inverse association. In general, an absolute (disregarding the sign) r value below 0.3 indicates a weak association, 0.3 to < 0.6 is fair association, 0.6 to < 0.8 is a moderate association, and \(\ge\) 0.8 indicates a strong association.
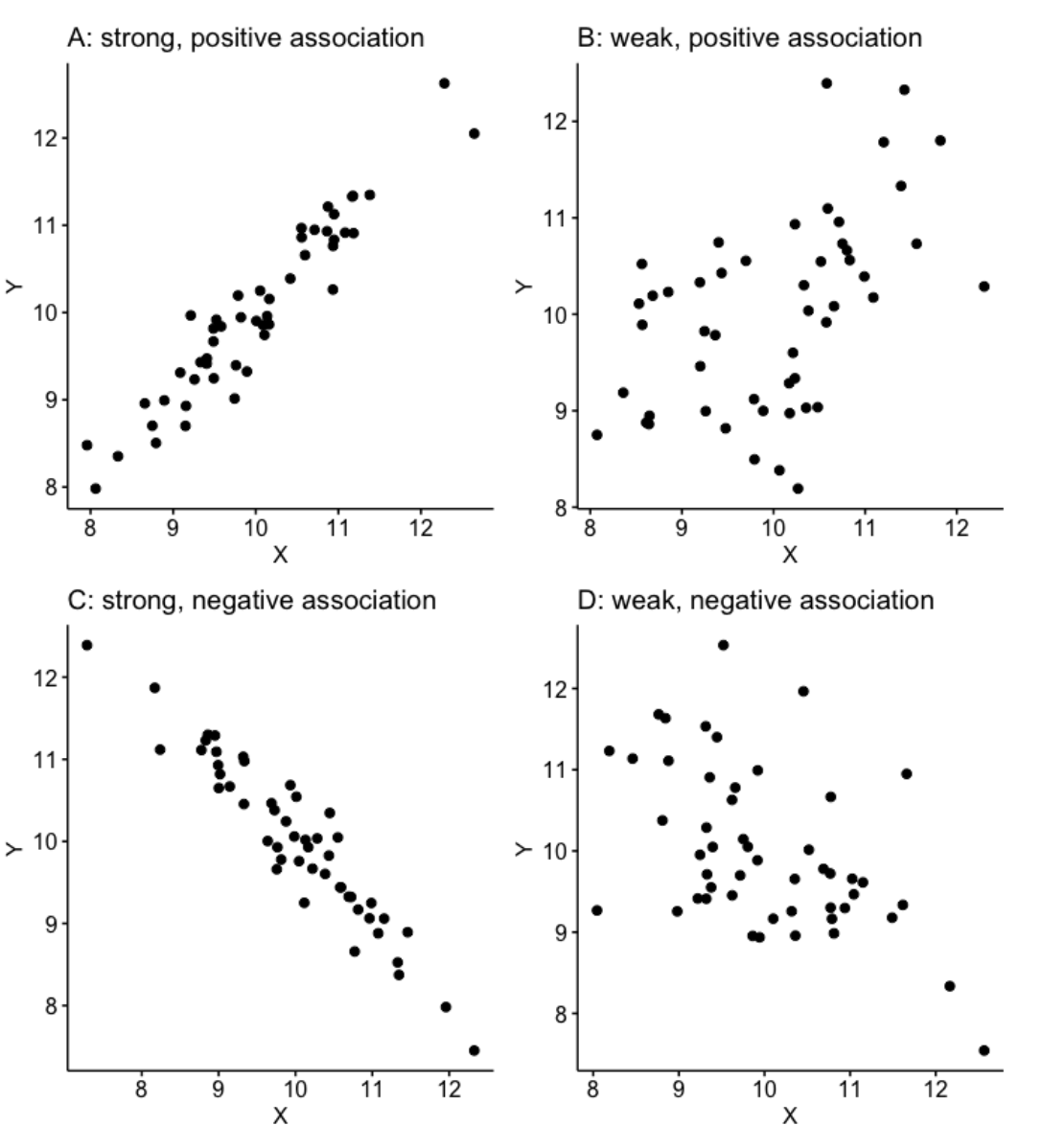
The correlation coefficient is positive when large values of one variable tend to occur with large values of the other, and small values of one variable (y) tend to occur with small values of the other (x) (Figure 8.2 (a and b)). For example, height and weight in healthy children or age and blood pressure.
The correlation coefficient is negative when large values of one variable tend to occur with small values of the other, and small values of one variable tend to occur with large values of the other (Figure 8.2 (c and d)). For example, percentage immunised against infectious diseases and under-five mortality rate.
It is possible to calculate a P-value associated with a correlation coefficient to test whether the correlation coefficient is different from zero. However, a correlation coefficient with a large P-value does not imply that there is no relationship between \(x\) and \(y\), because the correlation coefficient only tests for a linear association and there may be a non-linear relationship such as a curved or irregular relationship.
The assumptions for using a Pearson’s correlation coefficient are that:
- observations are independent;
- both variables are continuous variables;
- the relationship between the two variables is linear.
There is a further assumption that the data follow a bivariate normal distribution. This assumes: y follows a normal distribution for given values of x; and x follows a normal distribution for given values of y. This is quite a technical assumption that we do not discuss further.
There are two types of correlation coefficients– the correct one to use is determined by the nature of the variables as shown in Table 8.1.
Correlation coefficient | Application |
|---|---|
Pearson’s correlation coefficient: r | Both variables are continuous and a bivariate normal distribution can be assumed |
Spearman’s rank correlation: ρ | Bivariate normality cannot be assumed. Also useful when at least one of the variables is ordinal |
Spearman’s \(\rho\) is calculated using the ranks of the data, rather than the actual values of the data. We will see further examples of such methods in Module 9, when we consider non-parametric tests, which are often based on ranks.
Correlation coefficients are often presented in the form of a correlation matrix which can display the correlation between a number of variables in a single table (Table 8.2).
| Height | FVC | |
| Height | 1 | 0.70 P < 0.0001 |
| FVC | 0.70 P < 0.0001 |
1 |
This correlation matrix shows that the Pearson’s correlation coefficient between height and lung function is 0.70 with P<0.0001 indicating very strong evidence of a linear association between height and FVC. A correlation matrix sometimes includes correlations between the same variable, indicated as a correlation coefficient of 1. For example, \(Height\) is perfectly correlated with itself (i.e. has a correlation coefficient of 1). Similarly, \(FVC\) is perfectly correlated with itself.
Correlation coefficients are rarely used as important statistics in their own right because they do not fully explain the relationship between the two variables and the range of the data has an important influence on the size of the coefficient. In addition, the statistical significance of the correlation coefficient is often over interpreted because a small correlation which is of no clinical importance can become statistically significant even with a relatively small sample size. For example, a poor correlation of 0.3 will be statistically significant if the sample size is large enough.
8.4 Linear regression
The nature of a relationship between two variables is more fully described using regression, where the relationship is described by a straight line.
Figure 8.3 shows our lung data with a fitted regression line.
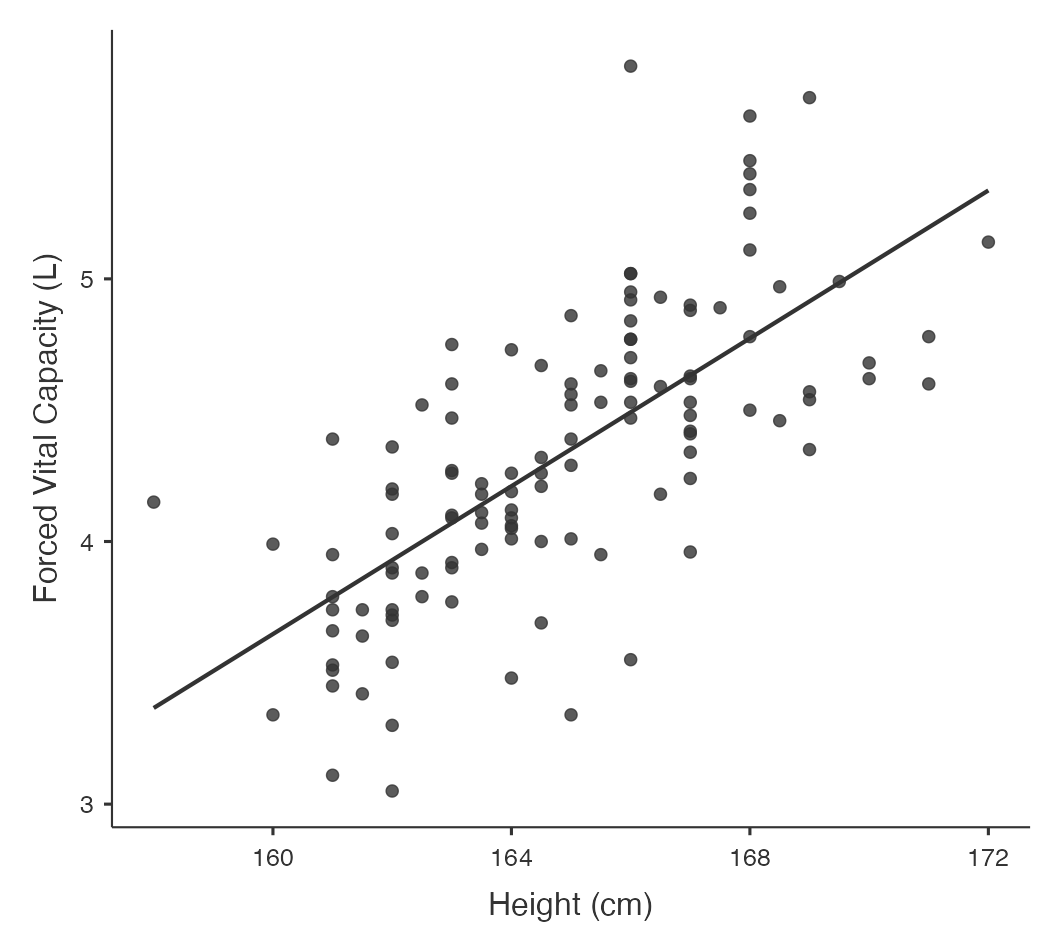
The line through the plot is called the line of ‘best fit’ because the size of the deviations between the data points and the line is minimised in estimating the line.
Regression equations
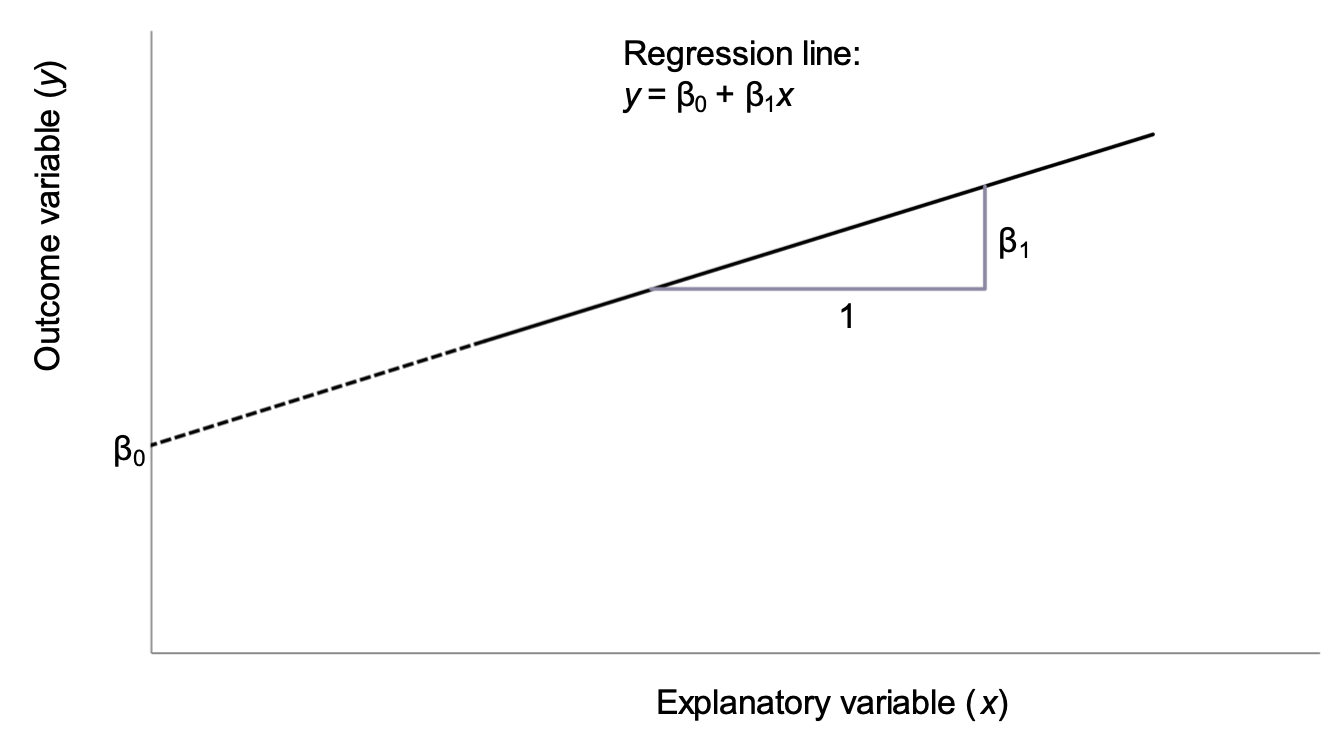
The mathematical equation for the line explains the relationship between two variables: \(y\), the outcome variable, and \(x\), the explanatory variable. The equation of the regression line is as follows:
\[y = \beta_{0} + \beta_{1}x\]
This line is shown in Figure 8.4 using the notation shown in Table 8.3.
Symbol | Interpretation |
|---|---|
y | The outcome variable |
x | The explanatory variable |
β0 | Intercept of the regression line |
β1 | Slope of the regression line |
The intercept is the point at which the regression line intersects with the y-axis when the value of \(x\) is zero. In most cases, the intercept does not have a biologically meaningful interpretation as the explanatory variable cannot take a value of zero. In our working example, the intercept is not meaningful as it is not possible for an adult to have a height of 0cm.
The slope of the line is the predicted change in the outcome variable \(y\) as the explanatory explanatory variable \(x\) increases by 1 unit.
An important concept is that regression predicts an expected value of \(y\) given an observed value of \(x\): any error around the explanatory variable is not taken into account.
8.5 Regression coefficients: estimation
The regression parameters \(\beta_{0}\) and \(\beta_{1}\) are true, unknown quantities (similar to \(\mu\) and \(\sigma\)), which are estimated using statistical software using the method of least squares. This method estimates the intercept and the slope, and also their variability (i.e. standard errors). Software is always used to estimate the regression parameters from a set of data.
Using the method of least squares:
- the intercept is estimated as \(b_0\);
- the slope is estimated as \(b_1\).
8.6 Regression coefficients: inference
We can use the estimated regression coefficients and their variability to calculate 95% confidence intervals. Here, a t-value from a t-distribution with \(n - 2\) degrees of freedom is used:
- 95% confidence interval for intercept: \(b_0 \pm t_{n-2} \times SE(b_0)\)
- 95% confidence interval for slope: \(b_1 \pm t_{n-2} \times SE(b_1)\)
Note that as the constant (\(b_0\)) is not often biologically plausible, the 95% confidence interval for the constant is often not reported.
The significance of the estimated slope (and less commonly, intercept) can be tested using a t-test. The null hypotheses and the alternative hypothesis for testing the slope of a simple linear regression model are:
- H0: \(\beta_1 = 0\)
- H1: \(\beta_1 \ne 0\)
To test the null hypothesis for the regression coefficient \(\beta_1\), the following t-test is used:
\[t = b_1 /SE(b_1)\]
This will give a t statistic which can be referred to a t distribution with n − 2 degrees of freedom to calculate the corresponding P-value.
Table 8.4 shows the estimated regression coefficients for our working example.
Term | Estimate | Standard error | t value | P value | 95% Confidence interval |
|---|---|---|---|---|---|
Intercept | -18.87 | 2.194 | t=-8.60, 118df | <0.001 | -23.22 to -14.53 |
Height | 0.14 | 0.013 | t=10.58, 118df | <0.001 | 0.11 to 0.17 |
From this output, we see that the slope is estimated as 0.14 with an estimated intercept of -18.87. Therefore, the regression equation is estimated as:
FVC (L) = − 18.87 + (0.14 \(\times\) Height in cm)
There is very strong evidence of a linear association between FVC and height in cm (P < 0.001).
This equation can be used to predict FVC for a person of a given height. For example, the predicted FVC for a person 165 cm tall is estimated as:
FVC = − 18.87347 + (0.1407567 \(\times\) 165.0) = 4.40 L.
Note that for the purpose of prediction we have kept all the decimal places in the coefficients to avoid rounding error in the intermediate calculation.
Fit of a linear regression model
After fitting a linear regression model, it is important to know how well the model fits the observed data. One way of assessing the model fit is to compute a statistic called coefficient of determination, denoted by \(R^2\). It is the square of the Pearson correlation coefficient \(r: r^2 = R^2\). Since the range of \(r\) is from −1 to 1, \(R^2\) must lie between 0 and 1.
\(R^2\) can be interpreted as the proportion of variability in y that can be explained by variability in x. Hence, the following conditions may arise:
If \(R^2 = 1\), then all variation in y can be explained by variation of x and all data points fall on the regression line.
If \(R^2 = 0\), then none of the variation in y is related to x at all, and the variable x explains none of the variability in y.
If \(0 < R^2 <1\), then the variability of y can be partially explained by the variability in x. The larger the \(R^2\) value, the better is the fit of the regression model.
8.7 Assumptions for linear regression
Regression is robust to moderate degrees of non-normality in the variables, provided that the sample size is large enough and that there are no influential outliers. Also, the regression equation describes the relationship between the variables and this is not influenced as much by the spread of the data as the correlation coefficient is.
The assumptions that must be met when using linear regression are as follows:
- observations are independent;
- the relationship between the explanatory and the outcome variable is linear;
- the residuals are normally distributed.
A residual is defined as the difference between the observed and predicted outcome from the regression model. If the predicted value of the outcome variable is denoted by \(\hat y\) then:
\[ \text{Residual} = \text{observed} - \text{predicted} = y - \hat y\]
It is important for regression modelling that the data are collected in a period when the relationship remains constant. For example, in building a model to predict normal values for lung function the data must be collected when the participants have been resting and not exercising and people taking bronchodilator medications that influence lung capacity should be excluded. In regression, it is not so important that the variables themselves are normally distributed, but it is important that the residuals are. Scatter plots and specific diagnostic tests can be used to check the regression assumptions. Some of these will not be covered in this introductory course but will be discussed in detail in the Regression Methods in Biostatistics course.
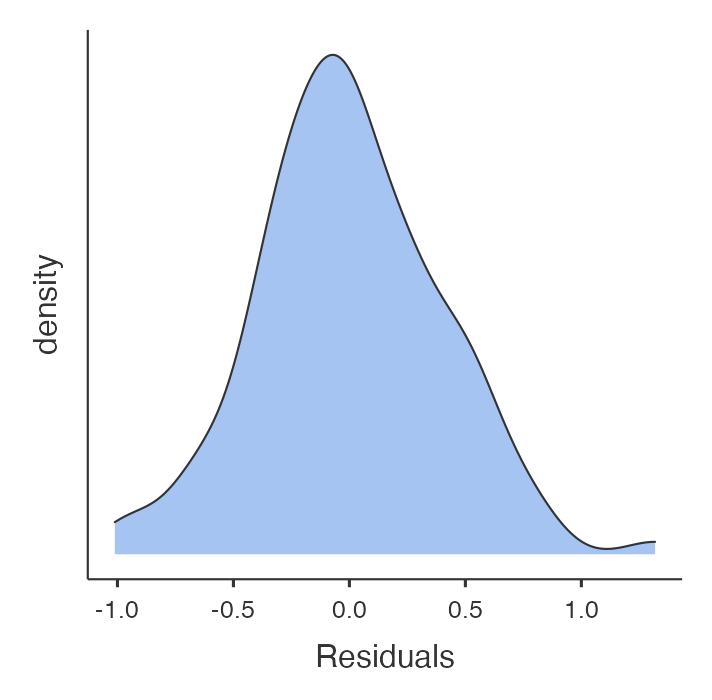
The distribution of the residuals should always be checked. Large residuals can indicate unusual points or points that may exert undue influence on the estimated regression slope.
The distribution of the residuals from the model is shown in Figure 8.5. The residuals are approximately normally distributed, with no outlying values.
8.8 Multiple linear regression
In the above example, we have only used a simple linear regression model of two continuous variables. Other more complex models can be built from this e.g. if we wanted to look at the effect of gender (male vs. female) as binary indicator in the model while adjusting for the effect of height. In that case we would include both the variables in the model as explanatory variables. In the same way we can include any number of explanatory variables (both continuous and categorical) in the model: this is called a multivariable model. Multivariable models are often used for building predictive equations, for example by using age, height, gender and smoking history to predict lung function, or to adjust for confounding and detect effect modification to investigate the association between an exposure and an outcome factor.
Multiple regression has an important role in investigating causality in epidemiology. The exposure variable under investigation must stay in the model and the effects of other variables which can be confounders or effect-modifiers are tested. The biological, psychological or social meaning of the variables in the model and their interactions are of great importance for interpreting theories of causality.
Other multivariable models include binary logistic regression for use with a binary outcome variable, or Cox regression for survival analyses. These models, together with multiple regression, will be taught in PHCM9517: Regression Methods in Biostatistics.
Jamovi notes
8.9 Creating a scatter plot
We will demonstrate using Jamovi for correlation and simple linear regression using the dataset mod08_lung_function.csv.
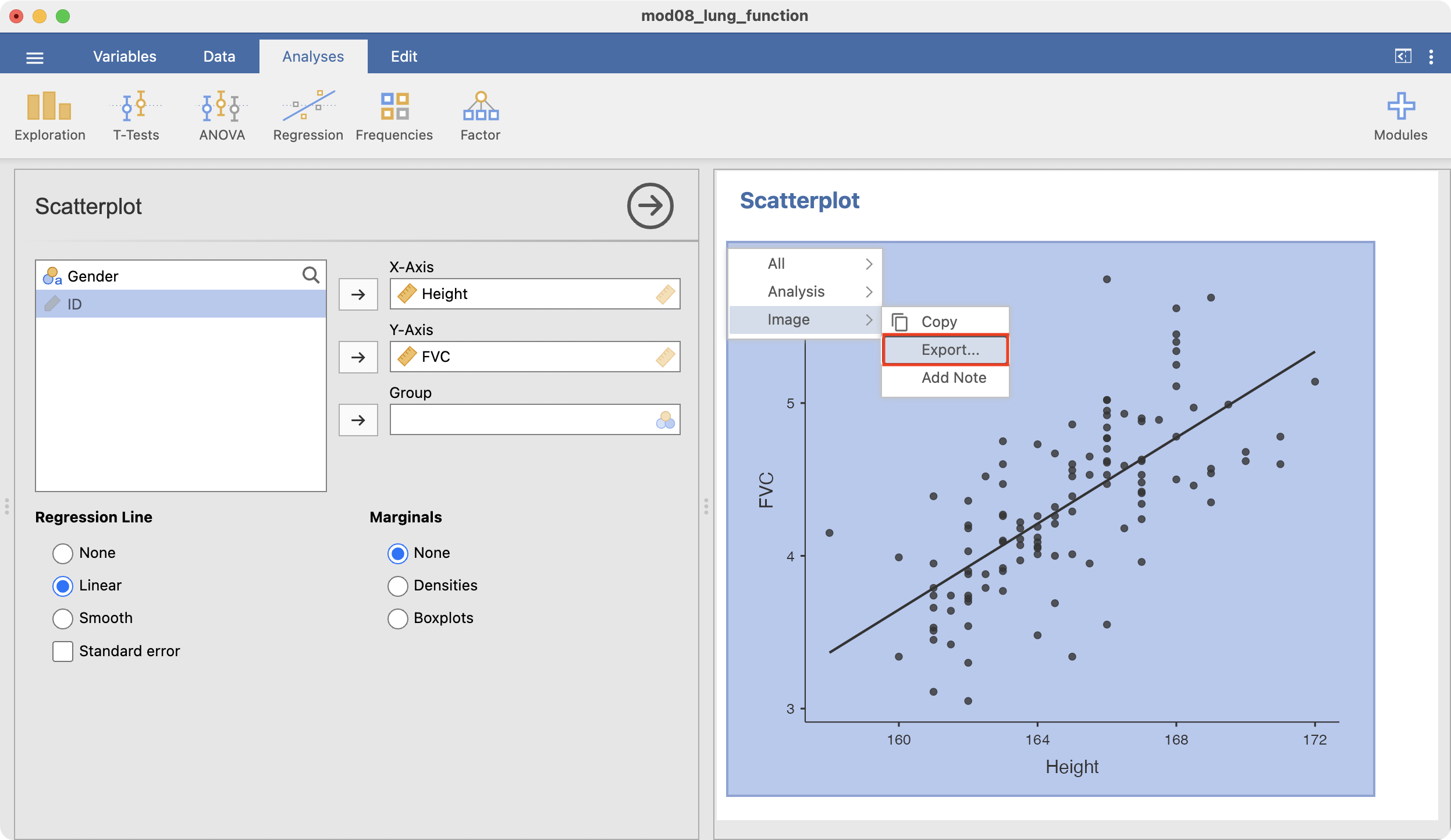
To create a scatter plot to explore the association between height and FVC, we use Scatterplot within the Exploration menu:
Choose Height for the X-Axis, and FVC for the Y-Axis, and the scatter-plot appears in the Output window:
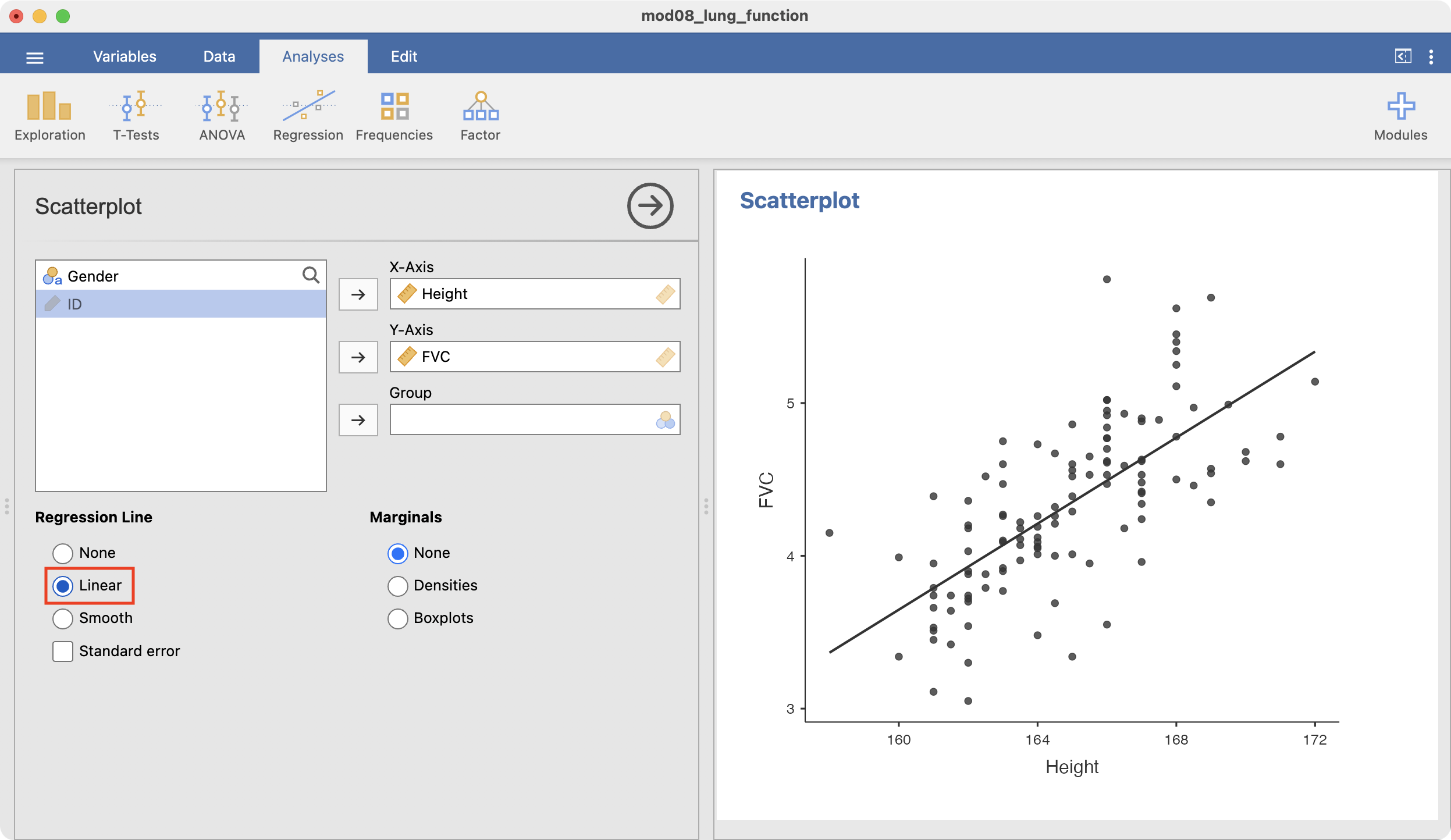
To add a fitted line, click the Linear option in the Regression Line section:
To save your graph, right-click the graph and choose Image > Export, and be sure to save your file as a PNG file:
8.10 Calculating a correlation coefficient
To calculate the Pearson’s correlation using the dataset mod08_lung_function.csv choose: Correlation Matrix within the Regression menu.
Select the two variables, FVC and Height in the Variables box, and a correlation matrix will be constructed, similar to Table 8.2.
8.11 Fitting a simple linear regression model
To fit a simple linear regression model, choose Regression > Linear Regression
Select FVC as the Dependent variable, and Height as a Covariate (Jamovi refers to continuous explanatory variables as covariates). To obtain the 95% confidence interval for the regression coefficients, scroll down to the Model Coefficients section and click the Confidence interval option for Estimate.
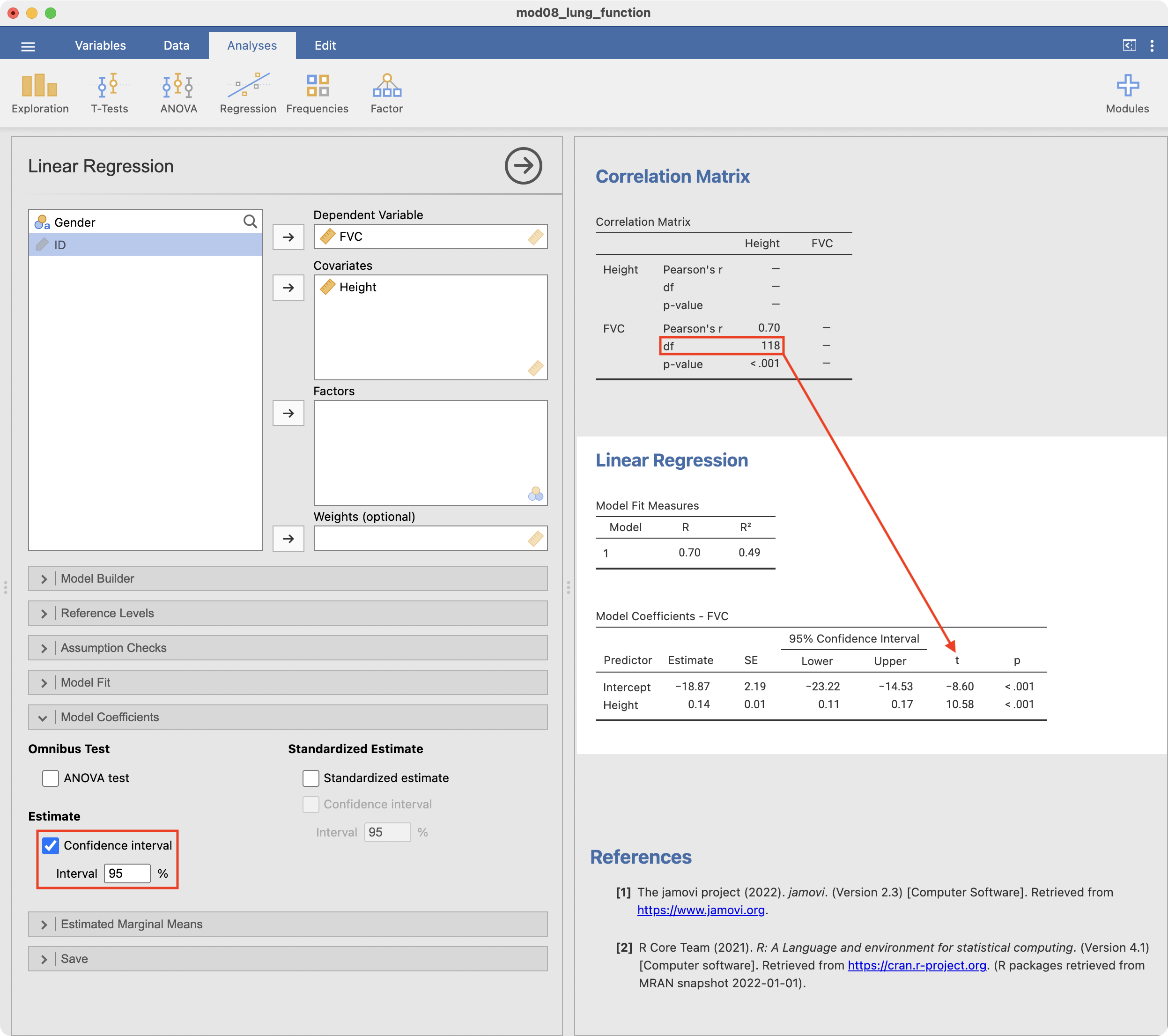
You will notice that the Jamovi output does not provide the degrees of freedom for the regression coefficient t-statistic. This is equivalent to the degrees of freedom in the preceding correlation matrix: in this case, 118 df.
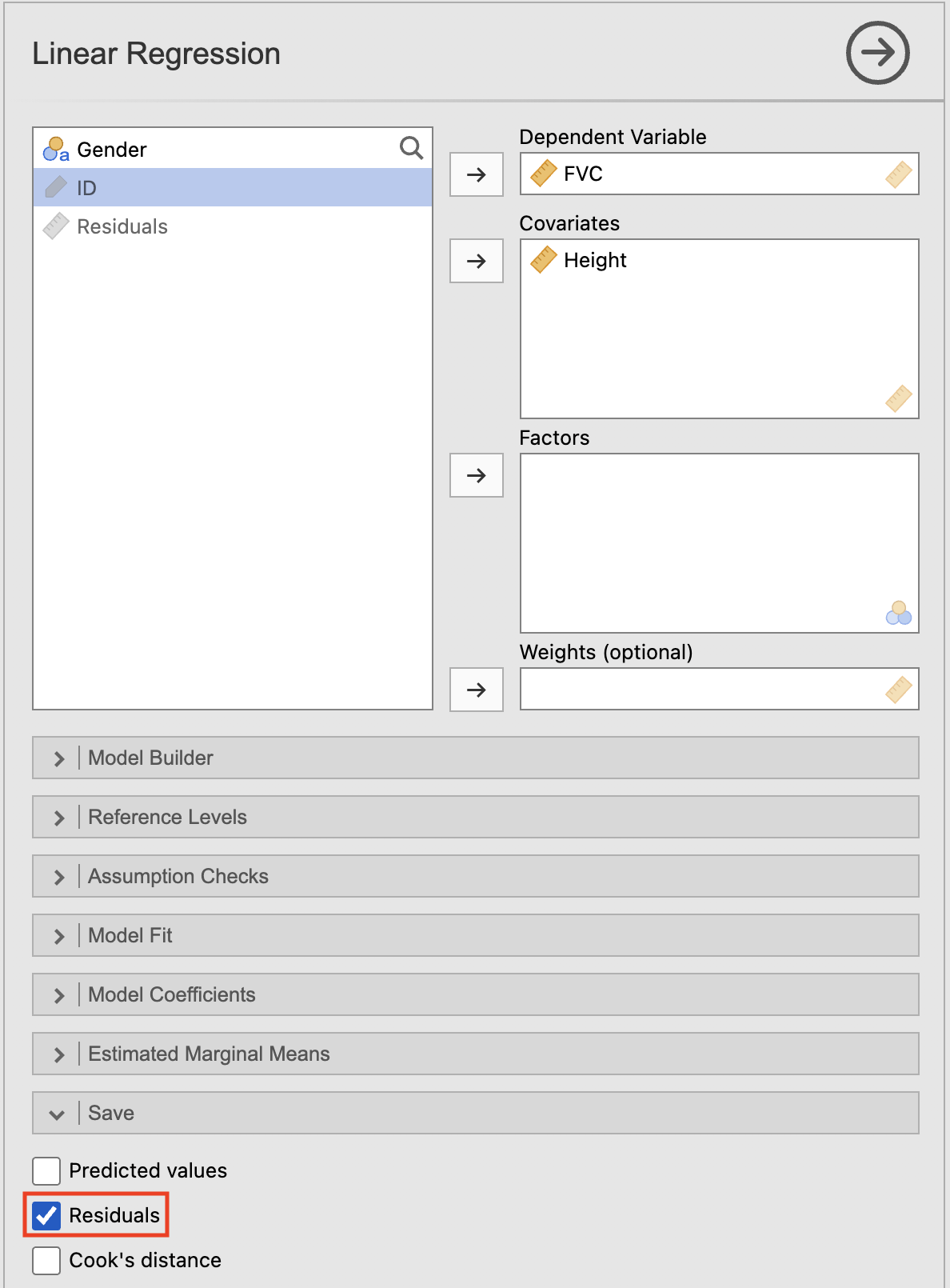
8.12 Plotting residuals from a simple linear regression
To plot the residuals, we first need to save them using the Save option within the Linear Regression command box:
This creates a new column of Residuals within our dataset:
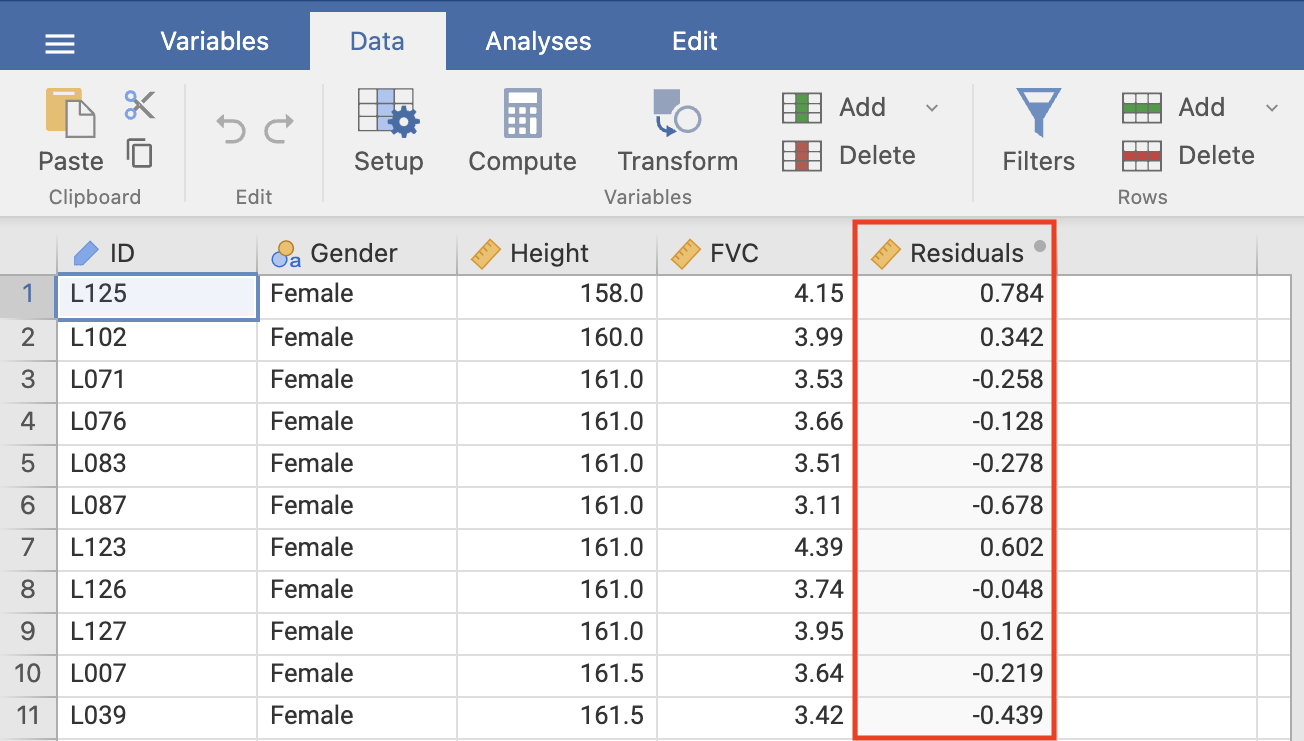
You can now check the assumption that the residuals are normally distributed by creating a density plot of the residuals using Exploration > Descriptives, as shown in Figure 8.5.
R notes
We will demonstrate using R for correlation and simple linear regression using the dataset mod08_lung_function.csv.
lung <- read.csv("data/examples/mod08_lung_function.csv")8.13 Creating a scatter plot
We can use the plot function to create a scatter plot to explore the association between height and FVC, assigning meaningful labels with the xlab and ylab commands:
plot(x=lung$Height, y=lung$FVC,
xlab="Height (cm)",
ylab="Forced vital capacity (L)")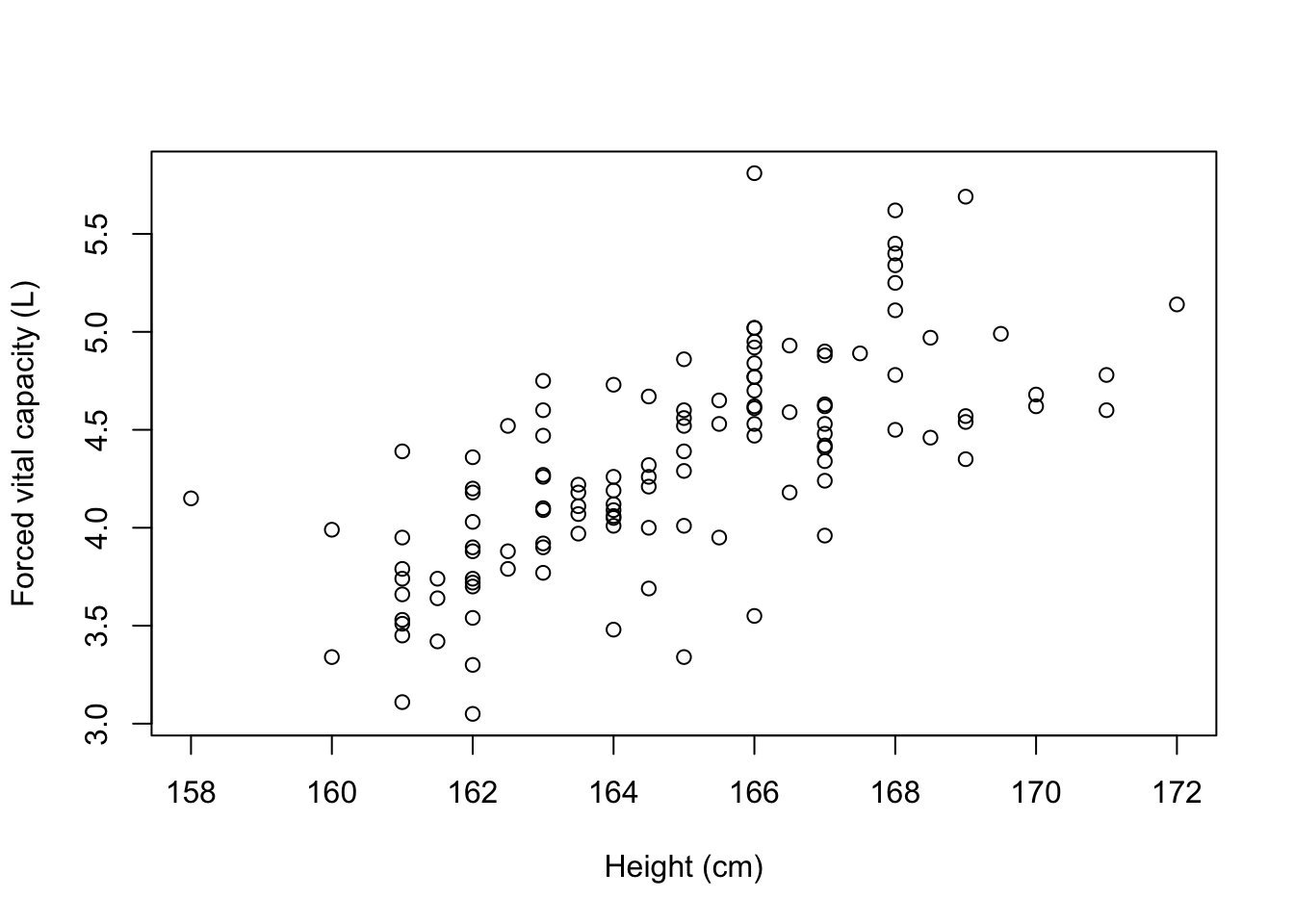
To add a fitted line, we can use the abline() function which adds a straight line to the plot. The equation of this straight line will be determined from the estimated regression line, which we specify with the lm() function, which fits a linear model.
The basic syntax of the lm() function is: lm(y ~ x) where y represents the outcome variable, and x represents the explanatory variable. Putting this all together:
plot(x=lung$Height, y=lung$FVC,
xlab="Height (cm)",
ylab="Forced vital capacity (L)")
abline(lm(lung$FVC ~ lung$Height))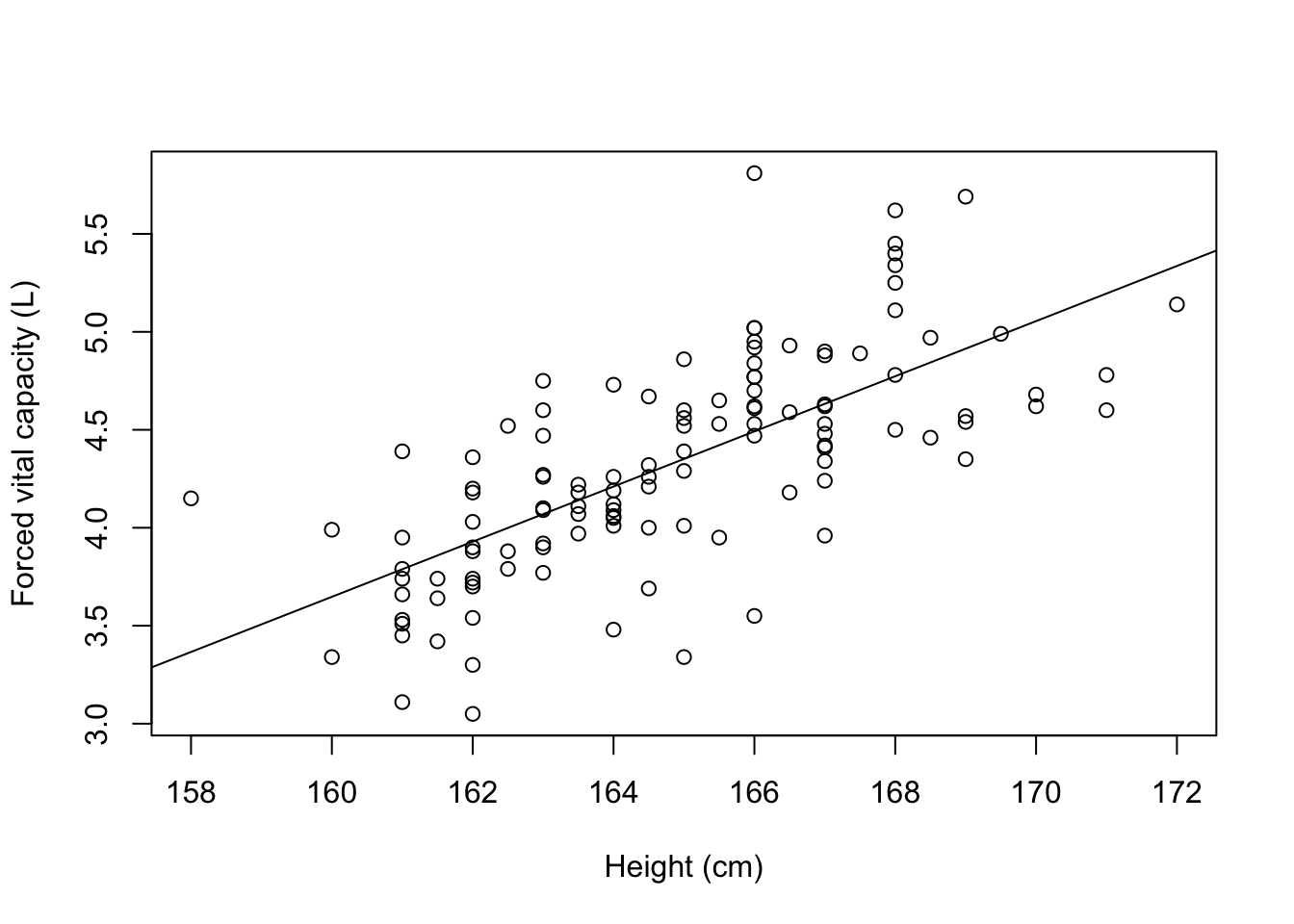
Note: to obtain output similar to Jamovi output, we can use the scatr package:
# Install scatr if required:
# install.packages("scatr")
library(scatr)
scat(data=lung, x="Height", y="FVC", line="linear")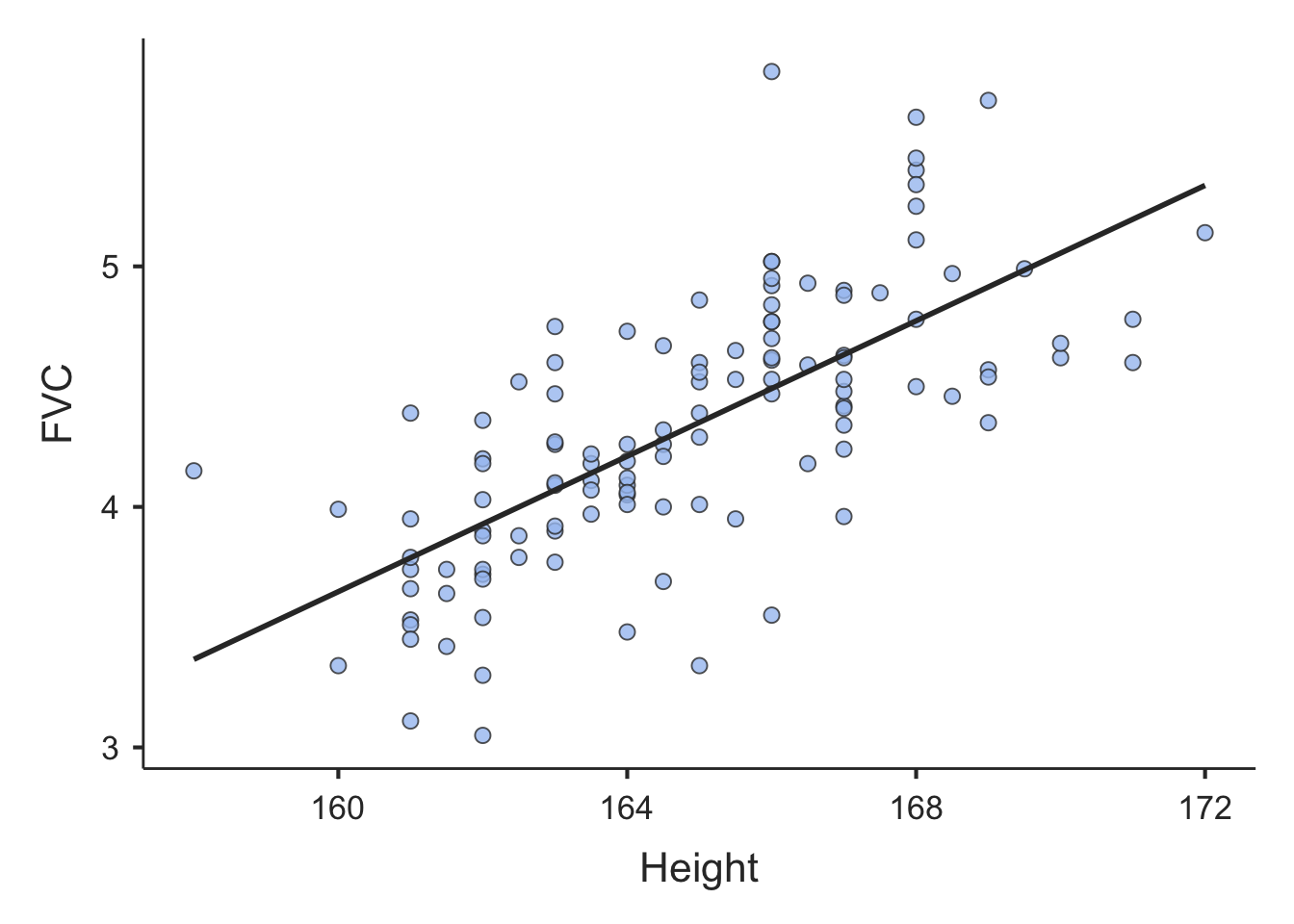
Calculating a correlation coefficient
We can use the corrMatrix function in the Jamovi package to calculate a Pearson’s correlation coefficient:
corrMatrix(data=lung, vars=c(Height, FVC))
CORRELATION MATRIX
Correlation Matrix
────────────────────────────────────────────────────
Height FVC
────────────────────────────────────────────────────
Height Pearson's r —
df —
p-value —
FVC Pearson's r 0.6976279 —
df 118 —
p-value < .0000001 —
──────────────────────────────────────────────────── 8.14 Fitting a simple linear regression model
We can use the lm function to fit a simple linear regression model, specifying the model as y ~ x where y represents the outcome variable, and x represents the explanatory variable. Using mod08_lung_function.csv, we can quantify the relationship between FVC and height:
lm(FVC ~ Height, data=lung)
Call:
lm(formula = FVC ~ Height, data = lung)
Coefficients:
(Intercept) Height
-18.8735 0.1408 The default output from the lm function is rather sparse. We can obtain much more useful information by defining the linear regression model as an object, then using the summary() function:
model <- lm(FVC ~ Height, data=lung)
summary(model)
Call:
lm(formula = FVC ~ Height, data = lung)
Residuals:
Min 1Q Median 3Q Max
-1.01139 -0.23643 -0.02082 0.24918 1.31786
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -18.87347 2.19365 -8.604 3.89e-14 ***
Height 0.14076 0.01331 10.577 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.3965 on 118 degrees of freedom
Multiple R-squared: 0.4867, Adjusted R-squared: 0.4823
F-statistic: 111.9 on 1 and 118 DF, p-value: < 2.2e-16Finally, we can obtain 95% confidence intervals for the regression coefficients using the confint function:
confint(model) 2.5 % 97.5 %
(Intercept) -23.2174967 -14.5294441
Height 0.1144042 0.1671092Note that the output for R looks slightly different from the Jamovi output, the numerical values are identical.
8.15 Plotting residuals from a simple linear regression
We can use the resid function to obtain the residuals from a saved model. These residuals can then be plotted using a density plot in the usual way:
residuals <- resid(model)
plot(density(residuals))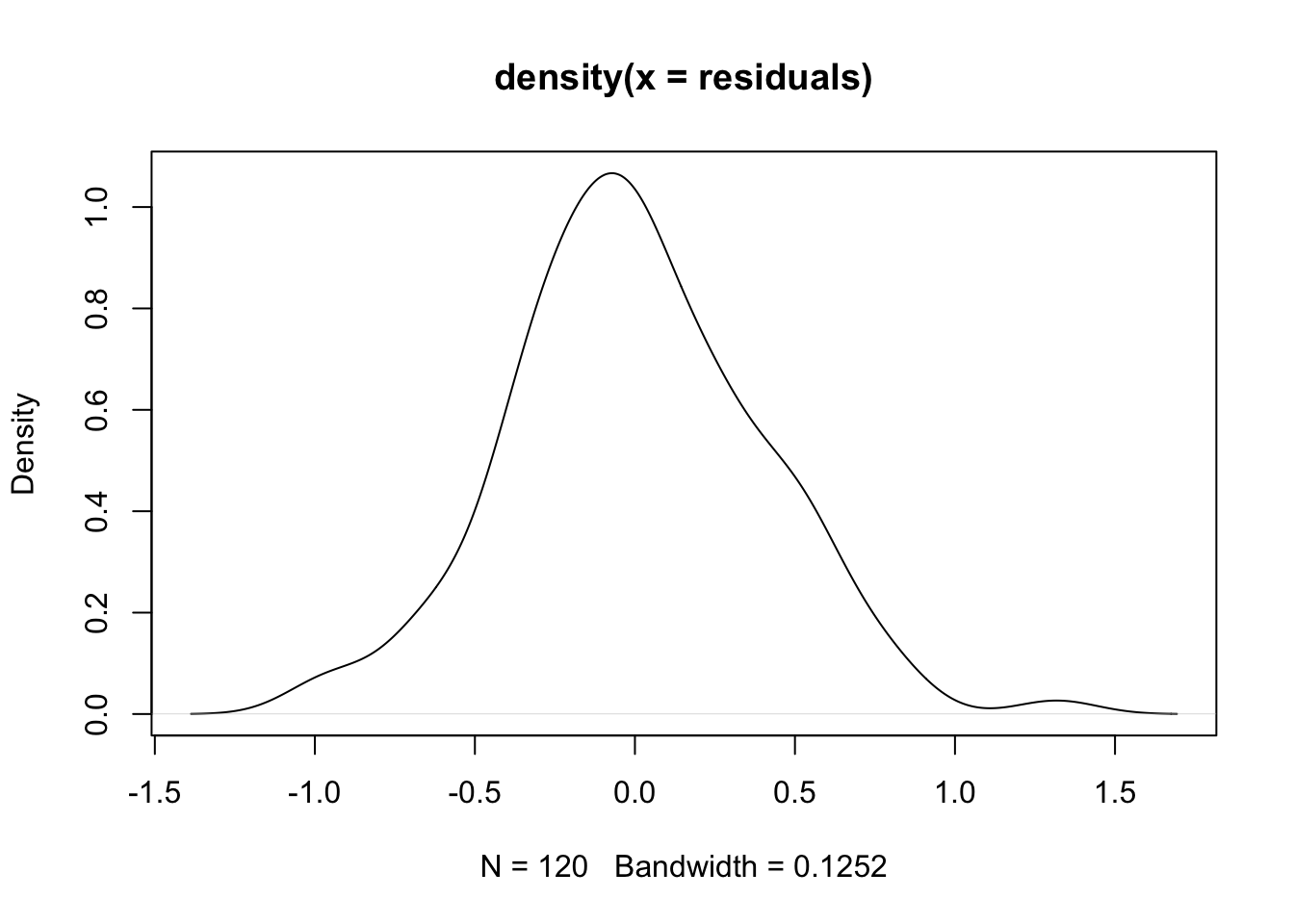
Activities
Activity 8.1
To investigate how body weight (kg) effects blood plasma volume (mL), data were collected from 30 participants and a simple linear regression analysis was conducted. The slope of the regression was 68 (95% confidence interval 52 to 84) and the intercept was −1570 (95% confidence interval −2655 to −492).
[You do not need software for this Activity]
- What is the outcome variable and explanatory (exposure) variable?
- Interpret the regression slope and its 95% CI
- Write the regression equation
- If we randomly sampled a person from the population and found that their weight is 80kg, what would be the predicted value of plasma volume for this person?
Activity 8.2
To examine whether age predicts IQ, data were collected on 104 people. Use the data in the file Activity_8.2.rds to answer the following questions.
- What is the outcome variable and the explanatory variable?
- Create a scatter plot with the two variables. What can you infer from the scatter plot?
- Obtain the correlation coefficient between age and IQ and interpret it.
- Conduct a simple linear regression and report the relationship between the two variables including the interpretation of the R2 value. Are the assumptions for linear regression met in this model?
- What could you infer about the association between age and IQ in the population, based on the results of the regression analysis in this sample?
Activity 8.3
Which of the following correlation coefficients indicates the weakest linear relationship and why?
- r = 0.72
- r = 0.41
- r = 0.13
- r = −0.33
- r = −0.84
Activity 8.4
Are the following statements true or false?
- If a correlation coefficient is closer to 1.00 than to 0.00, this indicates that the outcome is caused by the exposure.
- If a researcher has data on two variables, there will be a higher correlation if the two means are close together and a lower correlation if the two means are far apart.
Supplementary Activity 8.5
A cross-sectional study was conducted to examine the association between gestational age and systolic blood pressure in low birthweight babies. Data were collected at birth from 60 low birthweight babies and saved in the file Activity_8.5_babies.csv. The dataset contains the following variables:
- ID: participant ID number
- sbp: systolic blood pressure (mmHg)
- gestage: gestational age (weeks)
In this analysis, the researchers are interested in assessing the association between systolic blood pressure (the outcome variable) and gestational age (the explanatory variable).
NOTE: there is no need to apply clinical knowledge to the values of systolic blood pressure.
- Produce a scatter plot summarising the relationship between systolic blood pressure and gestational age, and describe this relationship.
- Estimate the correlation coefficient between systolic blood pressure and gestational age, and interpret it.
- Fit a simple linear regression model predicting systolic blood pressure from gestational age, and present the estimated regression equation.
- Are the assumptions of simple linear regression satisfied for your regression model? Provide evidence to support your claim.
- Summarise your regression model in a brief conclusion.